
Apple Explains How ‘Hey Siri’ Actually Works
 iPhone Mod
iPhone Mod
Toggle Dark Mode
Apple launched its official Machine Learning Journal earlier this year, which was designed as a blog-type forum for sharing the latest developments pertaining to the company’s ongoing artificial intelligence (AI) and machine learning projects. In its first post published July 19, the tech-giant showcased its AI ambitions as they relate to improving image recognition using neural networks, highlighting the complexities of AI-based neural net training of aggregated images.
Now, in its most recent blog post published Wednesday morning, Apple’s Siri team seeks to explain (in no uncertain terms) how the software powering its always-on “Hey Siri” command works on our iPhones and Apple Watches, and specifically how iOS and watchOS uses an advanced neural network to convert the acoustics (patterns and frequencies) of a users’ voice, while filtering out all other peripheral noises.
How Does ‘Hey Siri’ Work?
Hey Siri is based on a relatively complex system, which is almost exclusively regulated in the cloud via Apple’s servers — however it’s also reliant on a component dubbed “the detector.” Shown in the diagram below, Apple’s Siri team describes the detector as ‘the trigger,’ in other words, which acts as a “specialized speech recognition” engine that’s calibrated to run continuously in the background listening for its wake-up command, and filtering peripheral noise, by employing a powerful deep neural network.
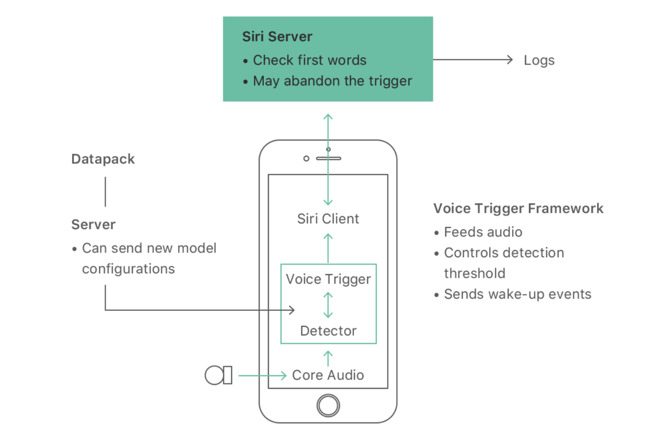
- “The microphone in an iPhone or Apple Watch turns your voice into a stream of instantaneous waveform samples, at a rate of 16000 per second,” the post reads, adding that “a spectrum analysis stage” then kicks in to convert those waveform voice samples into a “stream sequence of frames, each describing the sound spectrum of approximately 0.01 sec.”
- These voice stream sequences are then processed via Apple’s Deep Neural Network in 0.2 second fragments, which the author notes is just enough time for the system to classify what it’s actually listening to.
- This information is then passed on to the rest of iOS or watchOS, and from there, it’s dispatched like rapid-fire to one of Apple’s massive Siri servers.
- Last but not least, the server is ultimately responsible for processing the voice waveform — and should it detect that anything other than ‘Hey Siri’ was spoken (even something remotely similar like ‘hey seriously’) a cancellation is instantly sent back to the iPhone or Apple Watch.
here are a couple of advanced tools Apple has baked in to help reduce error and maximize accuracy of the feature. For starters, the company has established several “sensitivity thresholds,” as outlined in the diagram below:
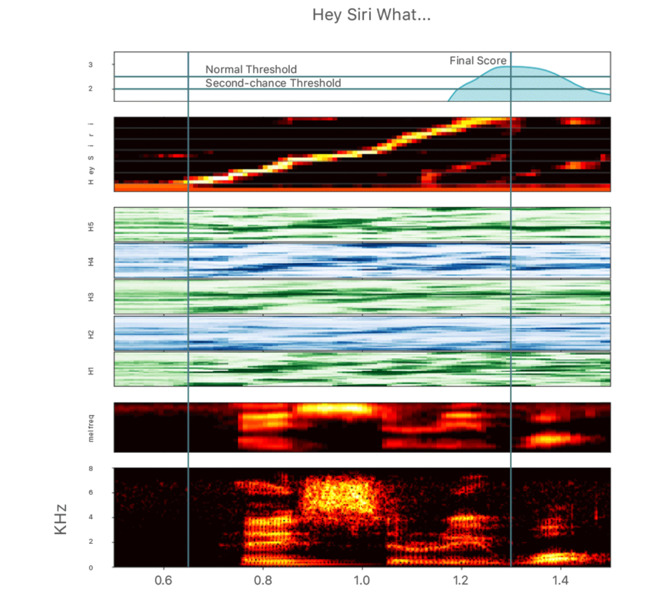
So if a voice waveform is registered in the ‘Second Chance’ (or median threshold), the software is calibrated to automatically issue a second opportunity for the user to speak, listening more intently for ‘Hey Siri’ the second time to ensure the phrase was actually spoken.
Apple has incorporated certain phonetic parameters for contextual-based and language-specific terms. For instance, Apple’s post notes that certain, similar-sounding words like “Syria”, “Cereal”, “Serious”, and “Seaweed” are always examined in their spoken context to minimize error.





